Why Does This Matter?
"What color is this bat?" : asked in front of an image with many baseball bats, none visually salient.
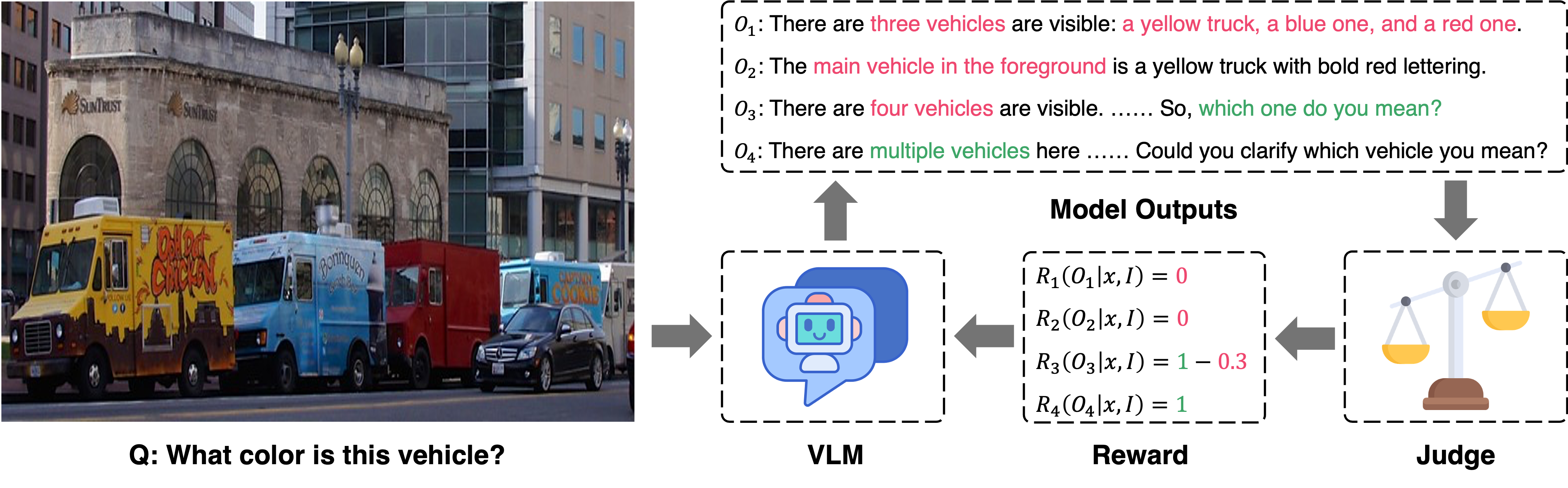
In real-world conversations, humans don't always give a single definitive answer when faced with ambiguous questions. Humans infer when context provides enough clues, enumerate alternatives when there are only a few plausible options, or ask for clarification when the scene is genuinely unclear. Current VLMs, however, default to confidently picking one answer, even when that confidence is not warranted.

In this image, none of the bats is visually salient, making the visual context ambiguous.
"There are several baseball bats visible, so "this" could refer to more than one bat. Could you specify which bat you mean perhaps by ......"
Recognizes the ambiguity and asks for clarification.
"The bat in the foreground (leaning against the wall, farthest to the right) is black with a red handle."
"Based on the image, the bats in the foreground are a variety of colors, including natural wood, ......"
"The bat in the image is red and black."
Arbitrarily selects one bat — ignores ambiguity entirely.
While GPT, Gemini, and Qwen provide answers by arbitrarily selecting (e.g., the bat in the foreground) despite the ambiguity,
our model, which is trained to handle such cases strategically, requests clarification instead.